Surface Form Competition
View the Project on GitHub peterwestuw/surface-form-competition-project
Surface Form Competition: Why the Highest Probability Answer Isn’t Always Right
Ari Holtzman*, Peter West*, Vered Shwartz, Yejin Choi, Luke Zettlemoyer
* = Joint investigators
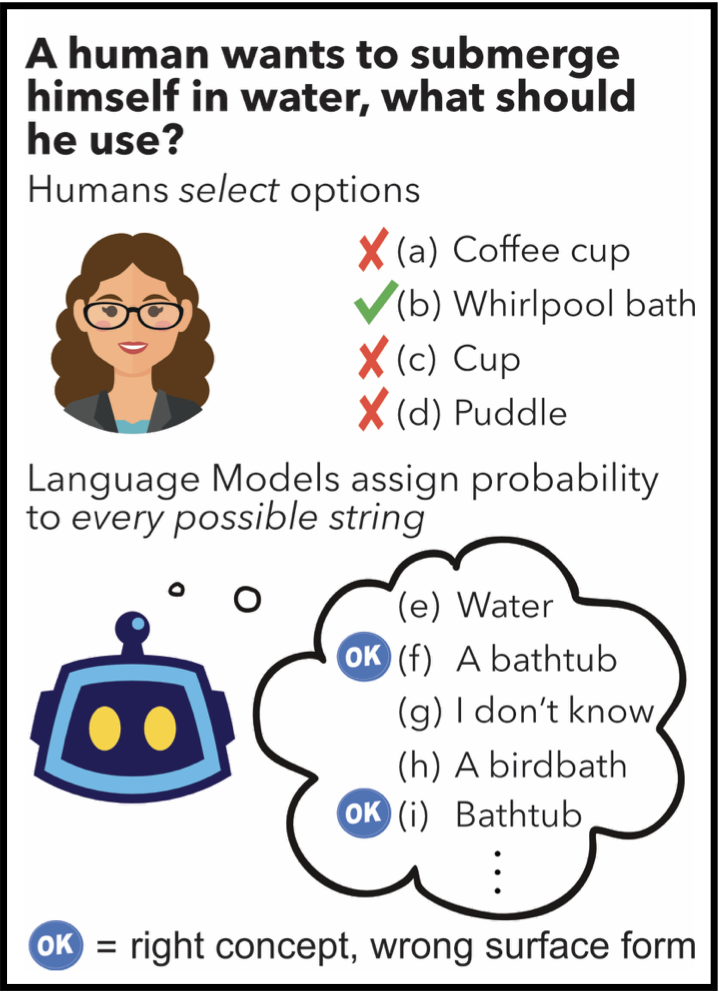
Large language models have shown promising results in zero-shotsettings (Brown et al.,2020; Radford et al., 2019). For example, they can perform multiple choice tasks simply by conditioning on a question and selecting the answer with the highest probability.
However, ranking by string probability can be problematic due to surface form competition-wherein different surface forms compete for probability mass, even if they represent the same underlying concept, e.g. “computer” and “PC.” Since probability mass is finite, this lowers the probability of the correctanswer, due to competition from other strings that are valid answers (but not one of the multiple choice options).
We introduce Domain Conditional Pointwise Mutual Information, an alternative scoring function that directly compensates for surface form competition by simply reweighing each option according to a term that is proportional to its a priori likelihood within the context of the specific zero-shot task. It achieves consistent gains in zero-shot performance over both calibrated (Zhao et al., 2021) and uncalibrated scoring functions on all GPT-2 and GPT-3 models over a variety of multiplechoice datasets.
Brown, T. et al. “Language Models are Few-Shot Learners.” ArXiv abs/2005.14165 (2020)
Radford, A. et al. “Language Models are Unsupervised Multitask Learners.” (2019)
Zhao, Tony et al. “Calibrate Before Use: Improving Few-Shot Performance of Language Models.” ArXiv abs/2102.09690 (2021)